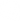 Interview Cake
Interview Cake
![An unsorted list [2, 7, 3, 9, 1, 6, 8, 4] is rearranged around a pivot element, 4. The resulting list is [2, 1, 3, 4, 7, 6, 8, 9]. [2, 1, 3] are less than the pivot and appear to the left; [7, 6, 8, 9] are greater than the pivot and appear to the right.](/images/svgs/quick_sort__preview.svg?bust=210)
Quick reference
| Complexity | |
|---|---|
| Worst case time | |
| Best case time | |
| Average case time | |
| Space |
Strengths:
- Fast. On average, quicksort runs in time, which scales well as n grows.
- Parallelizable. Quicksort divides the input into two sections, each of which can be sorted at the same time in parallel.
Weaknesses:
- Slow Worst-Case. In the worst case, quicksort can take time. While this isn't common, it makes quicksort undesirable in cases where any slow performance is unacceptable
One such case is the Linux kernel. They use heapsort instead of quicksort , so viruses and hackers can't exploit the slow worst-case time of sorting to tie up a machine's processor (and because heapsort has a lower space cost).
The High-Level Idea
Quicksort works by dividing the input into two smaller arrays: one with small items and the other with large items. Then, it recursively sorts both the smaller arrays.
Partitioning Around a Pivot
First, we grab the last item in the array. We'll call this item the pivot.
There are other ways to choose the pivot, but this is one of the simplest.
Next, we'll scoot things around until everything less than the pivot is to the left of the pivot, and everything greater than the pivot is to the right.
As an example, take this input array:
![An unsorted input list: [0, 8, 1, 2, 7, 9, 3, 4]](/images/svgs/quicksort__input_unsorted_list.svg?bust=210)
The 4 at the end will be our pivot.
![Given the input list [0, 8, 1, 2, 7, 9, 3, 4], the last element, 4, will be the "pivot."](/images/svgs/quicksort__input_unsorted_list_with_the_bolded_element_pivot.svg?bust=210)
So we want to get everything smaller than 4 to the left of 4 and everything larger to the right.
!["Partitioning" the list moves everything smaller than the pivot to the left and everything greater than the pivot to the right. The resulting list is [0, 3, 1, 2] [4] [9, 8, 7].](/images/svgs/quicksort__input_unsorted_list_with_pivot_at_the_middle.svg?bust=210)
We call this "partitioning," since we're dividing the input array into two parts (a smaller-than-the-pivot part and a larger-than-the-pivot part).
Here's how we do it:
The idea is to walk through the left-hand side of the array looking for items that don't belong there (because they're bigger than the pivot), and same thing with the right-hand side.
For our sample array:
We'll move two pointers—one on either end of the array— towards the middle. We'll skip over the pivot for now and add it in last.
![Our left pointer starts out at index 0, pointing to 0. Our right pointer starts out at index 6, pointing to 3. The last element, 4, is our pivot. We've got [0 (L), 8, 1, 2, 7, 9, 3 (R), 4 (P)].](/images/svgs/quicksort__input_unsorted_list_with_left_and_right_pointer.svg?bust=210)
We'll move the "left" pointer to the right until we get to an item that's larger than the pivot (which means it should go on the right-hand side of the array). 0 is less than 4, so we advance to the next item, 8. That's larger than the pivot and needs to be moved to the right-hand side of the list.
![Our left pointer advances from 0 to 8. Now, we've got [0, 8 (L), 1, 2, 7, 9, 3 (R), 4 (P)].](/images/svgs/quicksort__input_list_with_left_marker_under_8_and_3.svg?bust=210)
We've found something on the left that belongs on the right. Now we just need to find something on the right that belongs on the left, so we can swap the two of them.
So we'll move the "right" pointer to the left until we get to an item that's smaller than the pivot. 3 is smaller than 4, so we don't need to move the pointer at all.
Time to swap.
![We've got [0, 8 (L), 1, 2, 7, 9, 3 (R), 4 (P)]. We can swap the 8 and 3, producing [0, 3 (L), 1, 2, 7, 9, 8 (R), 4 (P)].](/images/svgs/quicksort__input_list_with_swappped_8_and_3.svg?bust=210)
And repeat. We start moving the left pointer to the right again, until we find another item that's larger than the pivot. We'll repeat this process until the "left" and "right" pointers cross each-other.
The "left" and "right" pointers will never stop on the same item. Do you see why?
The left item keeps moving until it hits something larger than the pivot. The right item keeps moving until it hits something less than or equal to the pivot.
If they stopped on the same item, then that item would have to simultaneously be larger than the pivot and smaller than the pivot. That's impossible!
So, we move the left pointer past 1 and 2, finally stopping at 7.
![We've got [0, 3 (L), 1, 2, 7, 9, 8 (R), 4 (P)]. The left pointer advances past 3, 1, and 2, stopping at 7. Now, we've got [0, 3, 1, 2, 7 (L), 9, 8 (R), 4 (P)].](/images/svgs/quicksort__input_list_with_moving_the_left_pointer_to_7.svg?bust=210)
And we move the right pointer past 8, 9, and 7, stopping at 2.
![We've got [0, 3, 1, 2, 7 (L), 9, 8 (R), 4 (P)]. The right pointer moves past 8, 9, and 7, stopping at 2. Now, we've got [0, 3, 1, 2 (R), 7 (L), 9, 8, 4 (P)].](/images/svgs/quicksort__input_list_with_moving_the_right_pointer_to_2.svg?bust=210)
Since "left" and "right" have crossed, we know that all the items smaller than the pivot are before "left" and all the items larger than the pivot are after "right".
Now we just have to put the pivot in the right spot. We can do that by swapping the pivot and the "left" item.
![We've got [0, 3, 1, 2 (R), 7 (L), 9, 8, 4 (P)]. Swapping the left element and the pivot, we have [0, 3, 1, 2, 4 (P), 9, 8, 7].](/images/svgs/quicksort__input_list_with_swapped_pivot_and_7.svg?bust=210)
The pivot is now where it needs to be in the final sorted array.
Recursively Sorting the Halves
Now that we've partitioned the input array into two smaller pieces, we can recursively sort each piece.
Just like merge sort, our base case will be an array with just one element, since that's already sorted.
Continuing the example above, we've already partitioned the input once, leaving us with two smaller arrays:
![[0, 3, 1, 2, 4 (P), 9, 8, 7] can be broken into two smaller lists around the pivot: [0, 3, 1, 2] and [9, 8, 7].](/images/svgs/quicksort__input__list_divided_on_two_smaller_lists.svg?bust=210)
Partitioning the subarray on the left:
![Given [0, 3, 1, 2], we assign the left, right, and pivot: [0 (L), 3, 1 (R), 2 (P)]. The left pointer advances to 3, the right pointer stays at 1, and we swap them, creating [0, 1 (L), 3 (R), 2 (P)]. THe left pointer advances to 3 and the right pointer moves left to 1. Swapping left with the pivot, we have [0, 1, 2 (P), 3]. Breaking the list around the pivot, we have [0, 1] and [3].](/images/svgs/quicksort__input_sublist_with_4_elements.svg?bust=210)
And, for the other array, we've got:
![Given [9, 8, 7], we assign the left, right, and pivot: [9 (L), 8 (R), 7 (P)]. The left pointer does not advance, but the right pointer moves backwards past the 8 and 9. Swapping the left with the pivot, we have [7 (P), 8, 9]. Breaking the list around the pivot, we have [] and [8, 9].](/images/svgs/quicksort__input_sublist_with_3_elements.svg?bust=210)
We'll continue recursing on the smaller remnants: [0, 1], [3], [7], and [8, 9], ultimately ending up with this result:
![Final sorted list: [0, 1, 2, 3, 4, 7, 8, 9].](/images/svgs/quicksort__input_sorted_list.svg?bust=210)
And, we're done!
Implementation
Here's how we'd code it up:
Time Complexity
Similar to merge sort, we can visualize quicksort's execution as recursively breaking up the input into two smaller pieces until we hit a base case.
![[0, 8, 1, 2, 7, 9, 3, 4] is partitioned to become [0, 3, 1, 2] [4] [9, 8, 7]. Those smaller lists are similarly partitioned into [0, 1] [2] [3] and [] [7] [8, 9]. Two element lists are broken into two sorted one-element lists. There are 4 total levels of partitioning, and each level involves all elements except the pivot(s) in the levels above.](/images/svgs/quicksort__input_list_breaking_to_sublists.svg?bust=210)
Each level in the diagram represents work, since we're doing a constant amount of work on each element in the array.
How many levels will there be? Assuming we pick a pivot that's close-ish to the median, we'll be dividing the arrays roughly in half each time. So, on average, we'll have levels, for a total average-case time complexity of .
However, if we get very unlucky with our pivot, in the worst case it's possible for the complexity to get as high as .
To see this, suppose the input is already sorted and we always pick our pivot from the end of the array.
Because the pivot's final position is all the way to the right, we end up with an empty right subarray and the whole rest of the array in the left subarray.
![[0, 1, 2, 3, 4, 7, 8, 9 (P)] is partitioned into [0, 1, 2, 3, 4, 7, 8] [9] []. Then, [0, 1, 2, 3, 4, 7, 8 (P)] is partitioned into [0, 1, 2, 3, 4, 7] [8]. We continue partitioning [0, 1, 2, 3, 4] [7]; [0, 1, 2, 3] [4]; [0, 1, 2] [3]; [0, 1] [2]; [0] [1]; [0]. There are n - 1 partitions total; each shrinks the remaining list by 1 element.](/images/svgs/quicksort__input_list_with_the_pivot_at_the_end.svg?bust=210)
This means we end up with levels, which costs time overall.
To avoid this poor worst-case behavior, some implementations shuffle the input before sorting. Others are more strategic about choosing their pivot, performing some heuristics to ensure the pivot is close-ish to the median.
Space Complexity
Quicksort operates on the input in place, without any extra copies or data structures. However, in the worst case where there are recursive calls, the call stack results in a space complexity of .
That said, with clever optimizations including tail calls, it's possible to avoid call stack space, bringing the space complexity down to just even in the worst case.
So, officially, quicksort requires space. In practice, most non-optimized implementations (including ours above) take more than that.
Interview coming up?
Get the free 7-day email crash course. You'll learn how to think algorithmically, so you can break down tricky coding interview questions.
No prior computer science training necessary—we'll get you up to speed quickly, skipping all the overly academic stuff.
No spam. One-click unsubscribe whenever.
You're in! Head over to your email inbox right now to read day one!
